✨ LLMjessica.com ✨
Document Clustering with LLM Labeling
Explore document clustering techniques to create an interactive visualization.
The goal of this demo is to explore and visualize topics within a corpus of text.
The data utilized in this project is a curated subset of metadata from research papers available on arXiv.
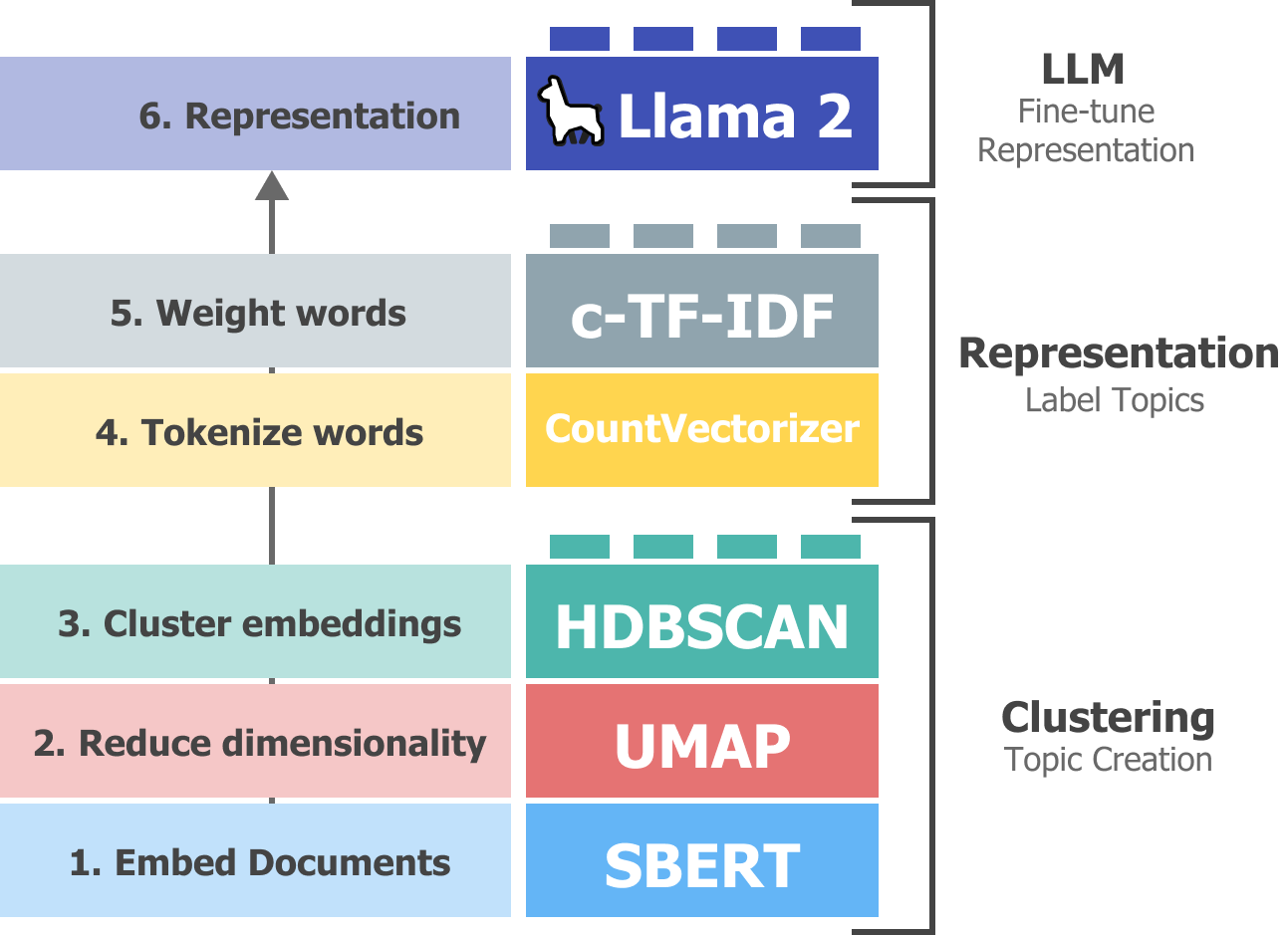
Using BERTopic, a Python library that combines traditional clustering methods with transformer-based embeddings, we identify coherent topics.
The pipeline includes multiple semi-supervised and unsupervised algorithms, such as dimensionality reduction techniques (UMAP) and clustering algorithms (HDBSCAN).
The goal is to group similar documents together, creating clusters that represent distinct topics.
We take this one step further by generating interpretable labels for these topics.
Llama2 is used to generate a fine-tuned representation of the clustered topics.
The Llama2 model is loaded with quantization to handle the LLM on limited GPU memory, leveraging 4-bit quantization.
To interpret the results of the BERTopic algorithm, a Plotly visualization is created where users can explore the labeled topics and documents. By setting custom labels derived from the text generation models, topics become more interpretable and user-friendly.